

Evaluating the quality of Large Language Models (LLM) and their diverse applications presents unique challenges. From generating engaging content to crafting detailed business reports, understanding and optimizing AI performance requires a strategic approach.
AI technology spans a wide range of tasks, from writing software code and producing business reports to analyzing market trends. This diversity makes it clear that a single, universal metric for measuring AI quality isn’t practical.
For example, evaluating AI-generated code involves integrating it into a development environment and running unit tests or integration tests to assess its functionality. On the other hand, assessing the quality of business reports produced by an LLM requires a different set of criteria.
This process includes extracting critical information, understanding its context, and ensuring the narrative is coherent—tasks that demand precise prompt engineering and comprehensive evaluation.
Metrics could be comparing statements of human written response vs AI-written response, or changes in the "human in the loop" systems.
Measuring the accuracy of AI-generated content, particularly for complex and unstructured outputs like market reports, presents several challenges. Key concerns include preventing the AI from generating incorrect information and assigning confidence scores to its assertions.
One effective solution is implementing advanced prompt techniques. By directing the LLM to use specific data points and clearly explain its reasoning, we can better align its outputs with human expectations. This approach, akin to running unit tests in software development, helps ensure the accuracy and reliability of AI-generated content.
Incorporating Continuous Integration/Continuous Deployment (CI/CD) principles into AI models can significantly enhance quality assessment. Imagine a system that automatically evaluates AI responses against predefined benchmarks, tracks pass/fail rates, and monitors performance trends.
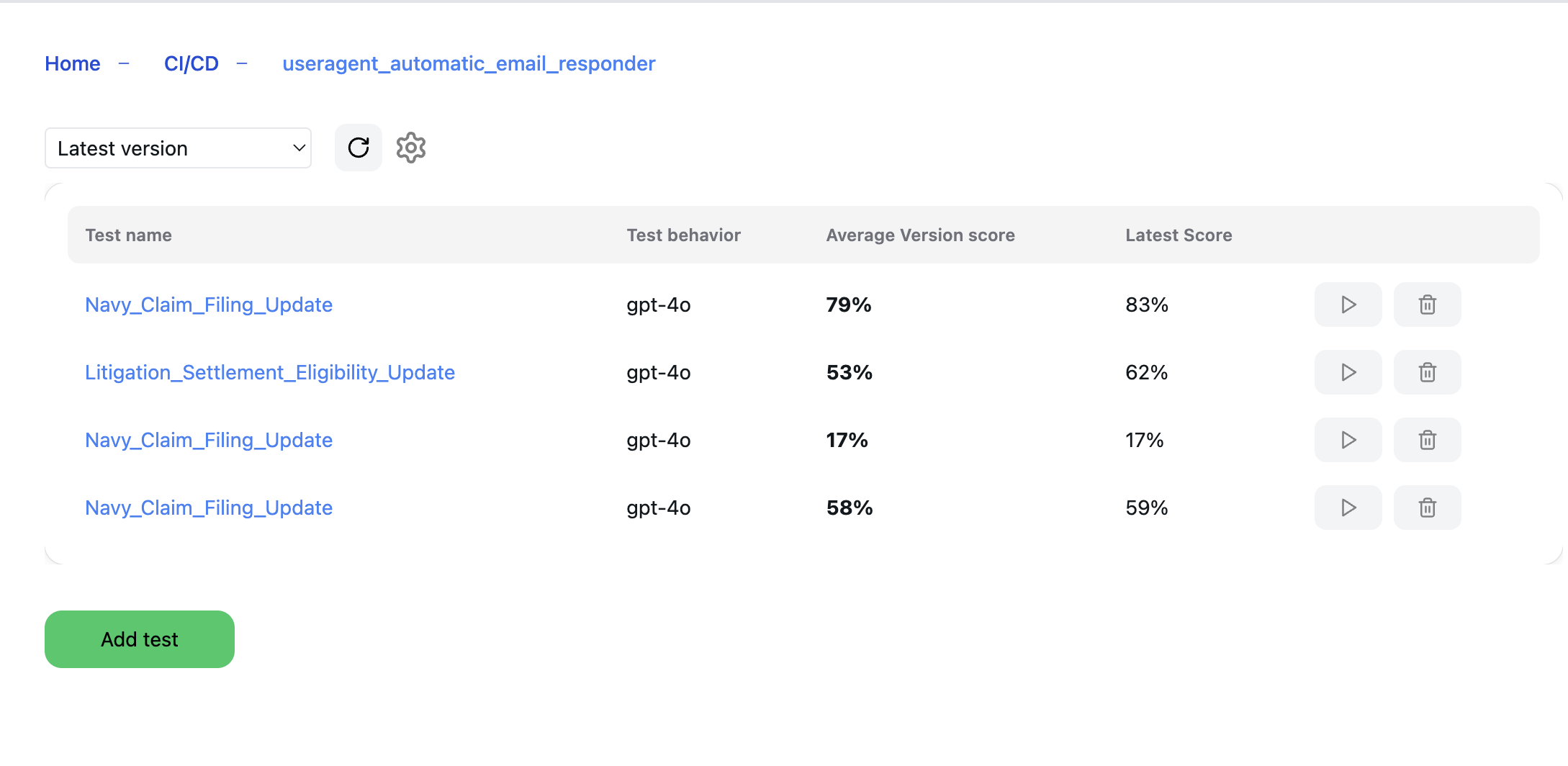
Such a system would not only automate quality assessments but also provide valuable insights into AI performance over time. This continuous feedback loop is crucial for maintaining and improving model reliability as new data and features are introduced.
The CI/CD pipeline for prompts is a benchmarking system, which defines how well the prompt executes its task. For evaluating generated text, such as a financial report, there are some techniques that can be used. This a sample of the steps we use, taken from flow-prompt.com:
This helps identify gaps in prompts and monitor if the output quality declines. By generating tests based on historical data, we can quickly see which data or data points are missing, causing the LLM to need more consideration. This allows us to generate more tests easily, especially when human feedback indicates that the LLM's response was inadequate, and provides the correct answer. We can quickly add that into the system.

The Hugging Face Open LLM Leaderboard is an excellent starting point, as users vote for their preferred outputs, ensuring a relatively unbiased assessment. We usually begin with the top-performing model there and refine our prompts for the leader of the board.
When prompts are crafted we cross-check outputs with other models. In our experience, Claude models tend to be more authentic, maintaining a consistent character and storyline, which is particularly valuable for reading financial reports. In contrast, GPT-4 Turbo often delivers a collection of facts without providing a cohesive explanation.
Despite significant advancements in AI, human oversight remains indispensable. Domain experts are essential for refining prompts and adjusting AI outputs to better fit evolving contexts and nuances. Empowering these experts to tailor AI behavior enhances the relevance and accuracy of the results.
For instance, consider a GenAI solution for market reports. If the LLM fails to account for the current month and its significance for trading, domain experts need to update the prompt themselves. They might revise it to include instructions like "consider what activity in the coming months could be based on the year's activities." This eliminates the need to involve software engineers for simple language adjustments, allowing domain experts to quickly iterate on their GenAI application.
It's important to teach individuals to take responsibility for their GenAI applications and instruct them in prompting techniques. Prompting is a language that encapsulates the thought processes behind decision-making.
Prompts may need to be updated frequently, weekly or even daily. Therefore, a system is needed to prevent disruptions and facilitate improvements. Recognizing this, we are moving in that direction.
Given that this field is relatively new, we are actively building these systems. We partner with the first CI/CD pipeline for prompts, the open-source library Prompt flow, and conduct our own research while working with clients to develop specific tools and technologies tailored to our customer needs.
Forte Group specializes in creating innovative GenAI solutions tailored to your business needs. Whether you have a clear problem that GenAI can solve or need help discovering the potential of AI in your business, we're here to guide you every step of the way.
Want to learn more about our AI services? We're happy to discuss your business goals related to AI and provide sample prompts for your use cases. Feel free to get in touch.
Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



