

Having access to stable test data is the biggest challenge to effective test automation for most organizations. And now, with the fast feedback required by DevOps, the consequences of a lack of good test data are even worse. That’s not going to cut it when most organizations now see quality as a key driver for business outcomes, according to The World Quality Report.
Too many organizations are faltering with test automation—and therefore DevOps—because they can’t, or don’t, manage test data appropriately. This is especially true of organizations implementing DevOps for legacy systems.
You can’t be successful in DevOps without effective test automation. And you can’t have effective test automation without properly managed test data. Here’s what you need to know to get your test data where it needs to be.
To be successful in DevOps you need a reliable set of automated tests that confirm that a given build is ready to move to the next stage in your pipeline. To be reliable, your tests must have access to a consistent, predictable set of data. So why do so many organizations struggle to provide stable test environments and data for their testing efforts?
The biggest challenges include:
When you have tests that input data that’s no longer appropriate for the current state of the system under test (SUT), or tests that expect a different response from what the SUT provided, you get frequent false positives and end up spending unnecessary cycles determining why the tests failed.
When you have tests that require data in specific states across multiple system components or integrated systems, you’ll end up spending significant amounts of time setting up data across systems—or worse, avoiding this testing altogether.
There are many other potential causes of test and data sync issues. Perhaps your data was modified by other activity in a shared environment, or the state of data changed over time. But no matter what the reason, unstable test data will prevent the reliable execution of automated tests on demand.
What you need is a strategy to provide sufficient volumes of predictable data on an ongoing basis for your automated tests.
It’s easy to say you need a test data management strategy; it’s much harder—yet critical—to first understand the specific problem you need to solve. The problem should be defined by the data requirements of your automated tests.
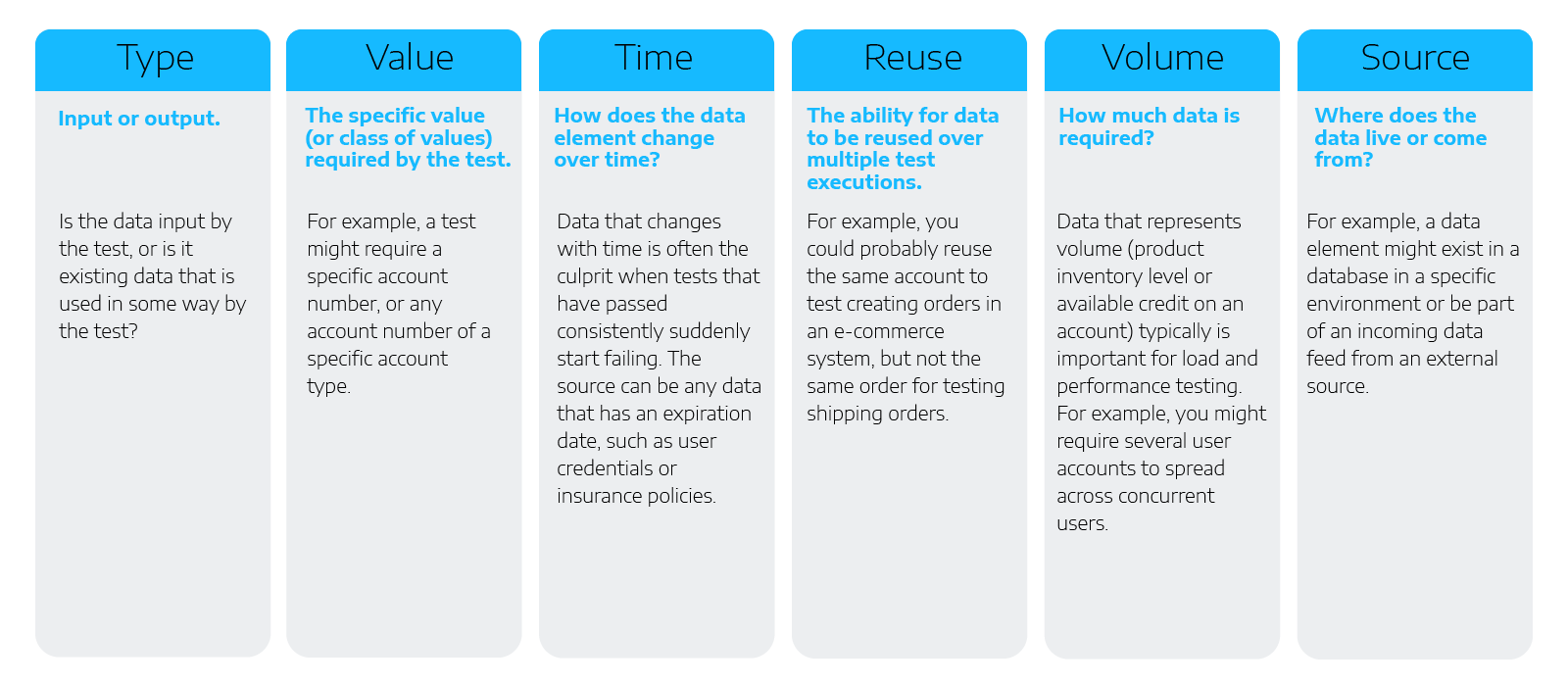
For each data element a given test requires, you need to understand the dimensions of the data, that is, the attributes that describe how it lives and behaves in the system under test.
Here are the critical data dimensions you need:
Once you understand your test data requirements, you need a strategy to manage that data. While it’s convenient to have a step-by-step recipe for managing test data, there are just too many variables across systems and technologies to make that feasible.
It’s better to identify a range of techniques that you can apply based on individual requirements. I’ve grouped common techniques into three high-level categories below: system/application, test suite, and external.
This involves dedicating data objects—such as certain accounts, products, or even an entire warehouse—for use by a specific automated test suite. This helps address issues associated with data changes in shared environments.
Here you move data in a known state (usually from production) to a test environment. While this technique is extremely common, it is not necessarily the most effective one—especially in a DevOps environment. Typically, the time required to perform even a partial refresh forces a cadence that is too slow for DevOps, and performing a synchronized reset across integrated systems/components can be complex and error-prone. In instances where a data refresh is feasible, you can make it more effective by combining it with data partitioning. This involves seeding dedicated test data in production so it’s available after each refresh.
The automated test suite can create/update the data it needs as a setup task before execution. This technique can be combined with data partitioning to further remediate test data issues. For example, a test might create inventory, but the SKU and inventory location are designated for automated test suite use only. This technique works best in situations where you can use APIs (or even direct data access) to adjust the data. Data setup through the user interface can be a slow process; it also suffers from the same reliability issues as any other UI-level test automation.
Similar to pre-test data creation, this technique uses post-test tasks to reset (i.e., add, modify, delete) data to a known state. As with pre-test data setup, you should perform this technique through API/data access whenever possible.
This involves adding a feature to your automated test framework to recognize data generation tags as opposed to hard-coded data values. This is useful in situations where test data must come from a specific timeframe on the current date. During execution, the framework generates the appropriate data based on the data tag, versus requiring that you maintain test cases before every execution.
This is similar to on-demand data generation but uses static data tags that represent a required data value that changes over time. You can store the current value of each static data tag in a central location where the framework can retrieve it at runtime.
Use test doubles (e.g., stubs, mocks, or virtualized services) in situations where it is difficult (or impossible) to control the data a test needs. This technique works best when there is a clear endpoint that you can replace with a test double, and can be more difficult to use with legacy or monolithic applications.
These are full-service test management tools that address several test data-related issues, including data generation, data masking, data sub-setting, and provisioning. Several commercial and open-source tools address parts of the test data management problem. While these tools are extremely powerful, their applicability to specific environments and technologies varies from one tool to another.
Organizations often start thinking about managing test data only after they begin experiencing issues like unreliable automated test execution. By that time a significant amount of test data-related technical debt will have accumulated.
The time to think about managing test data is before you start building your automated test suite. That’s also a good time to think about other constraints and dependencies related to your test automation efforts. A good way to do that is to use the Test Suite Canvas. This technique, originally developed by Katrina Clokie, engineering manager at the Bank of New Zealand, helps teams get a 360-degree view of what’s required to build and maintain their automated test suites.
Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



