


Do I believe that traditional performance testing is dead? No, not really, but I needed a controversial statement to grab your attention. So let me qualify that statement a bit to say, “Traditional performance testing as the ONLY evaluation of system performance is dead.”
To understand why, let’s look at what “traditional” performance testing generally looks like…
I spent a good portion of my career helping organizations set up centers of excellence that became very effective at executing this type of performance testing and enforcing the often stringent rules that went along with it.
Those rules essentially said that if you want us to test your app, you must do the following:

Even if the organization decides to play along with those rules, there’s a serious flaw. Let’s say we design, build and execute a big system-level performance test that takes many weeks before we get any results. What happens if we find out we have performance issues at this point? Our options are not good!
We either delay the release — which means we’re delaying delivering value to our customers, or we release and risk getting hit by the freight train.
This freight train comes in the form of lost revenue, brand value, and customer loyalty. It’s also the increased cost of remediation compared to finding and addressing issues early on.
But either way, our options are less than ideal.
At first glance, the logical approach might be to perform “traditional” performance testing at the end of each development sprint. The thought being that we can keep up if we start relatively small and build and maintain the performance test as the application grows. Of course, the reality is that there is no way that you can follow the “rules” of traditional performance testing if you’re taking an agile approach to development.
If you wait until new features are functionally complete and tested, there’s no time to enhance and maintain the performance test suite before the end of the sprint. We certainly can’t freeze code for an entire sprint (or, worse, sprints) while we develop and execute our performance test.
And it’s very unlikely that we’ll have anything that resembles a production environment, especially if we’re early on in building our app.
We end up trying to combine short/agile development cycles with lengthy/rigid performance tests.
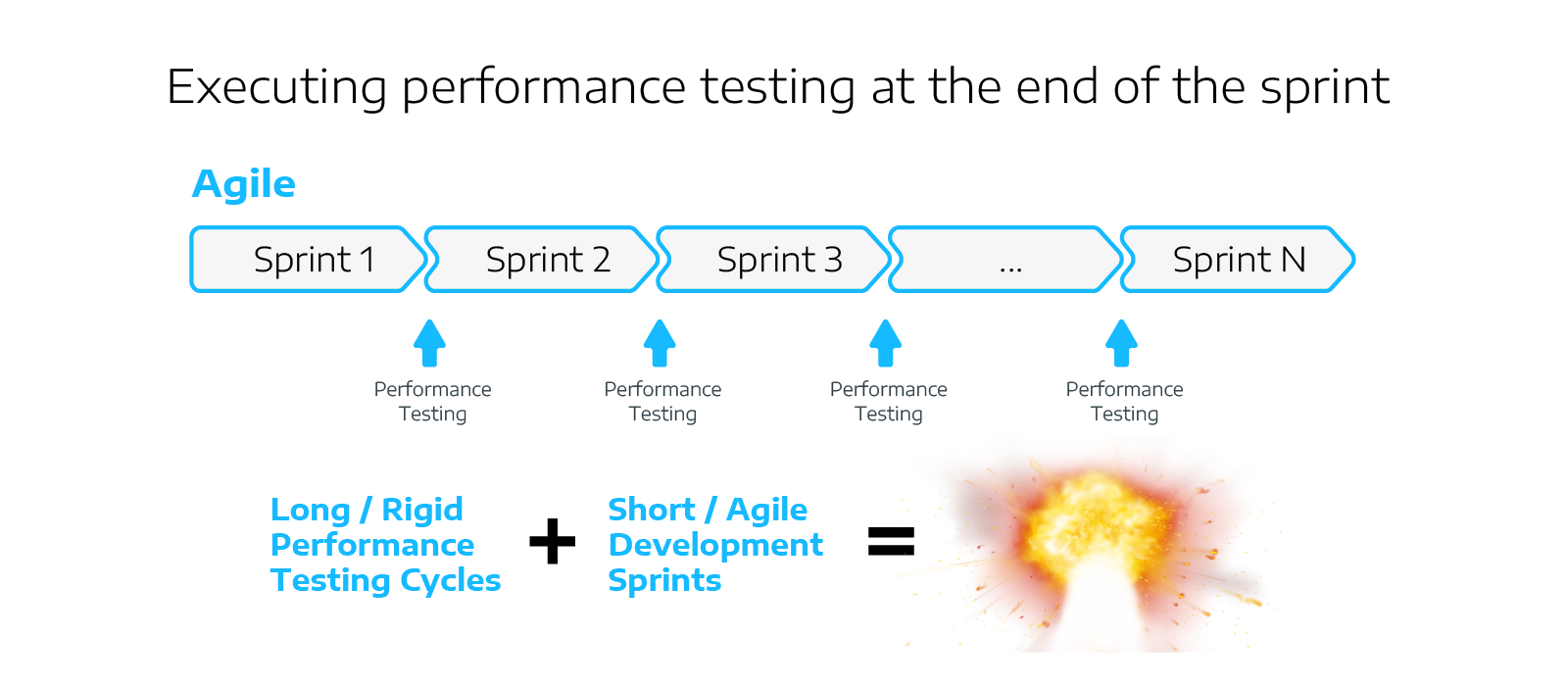
…and we end up with disaster!
I stubbornly banged my head against this wall for quite a while. I tried to solve the problem of shrinking the traditional system-level performance test into something that can be executed more frequently. It took a while, but I finally realized I was trying to solve the wrong problem. My goal was to get more frequent feedback on performance. However, I was naively assuming that I needed to do that at only the system level like I had been doing at the time for probably 20 or so years. I took a step back and began a bit of research. While there wasn’t too much information available related to performance testing — there was quite a bit of work being done about moving testing activities earlier in the development cycle. This was being done under the general umbrella of Continuous Testing.
The rest of this post summarizes the lessons I learned from an almost two-year journey with an organization as we evolved from performance testing immediately before major releases to a state where we could evaluate performance earlier and more frequently. We called this capability Continuous Performance Testing.
Let’s start by looking at what Continuous Performance Testing is NOT. As we learned the hard way, it’s not:
However, as we progressed on our journey, we came to understand that Continuous Performance Testing is the evaluation of performance at each stage (as appropriate) of the delivery pipeline. It’s also more frequent and visible performance feedback that allows us to trend performance data across builds.
Traditional performance testing doesn’t work in agile/DevOps cycles, but many organizations build software via a DevOps approach. Let’s take a look at how they are doing with regards to performance testing.
According to the 2019 State of DevOps report, which includes the most recent data on this particular topic, not very well. Even among elite DevOps performers, only 28 percent are including performance testing as part of the way they develop software.
Data from 2019 Accelerate State of DevOps Report
Low
Medium
High
Elite
Automated Unit Tests
57%
66%
84%
87%
Automated Acceptance Tests
28%
38%
48%
58%
Automated Performance Tests
18%
23%
18%
28%
Automated Security Tests
15%
28%
25%
31%
If the top DevOps performers are lagging in performance testing and analysis, there must be something standing in the way. In my experience, there are several things:
One of the enormous holes in most organizations is the failure to think about performance from the beginning. This “hole” was often created in older software development processes where understanding the system’s performance was someone else’s responsibility. The issue with that approach is surfacing performance issues too late to do anything about it.
A great way to address that is to consider performance requirements and factors when creating stories. As you’re building your backlog, think about performance factors that are important to your product. For example, for functionality related to searching for customer accounts in a call center app, the following performance factors might be relevant:
One thing we found when we first started doing this is that we got into a situation of analysis paralysis. We were trying to get very detailed performance-related acceptance criteria, but since this was new to the organization, they often didn’t have all the information to provide that data. So instead of calling them acceptance criteria, we began calling them “performance factors” to take away some formality. This helped us understand that we didn’t have to spend too much time getting every performance-related detail fleshed out. At this point, we’re just getting the performance factors out in the open for the entire team to see and not leaving it for a performance test engineer to worry about right before release.

General performance factors are a great starting point, but at some point, we’ll want to incorporate performance requirements more formally in our work. I’ve seen a handful of approaches and what’s right depends a bit on the organization and how they prefer to work.
One of the more popular approaches is to include performance requirements as constraints that specific (or all) stories need to meet. Performance requirements — like response time, support for a concurrency level, or throughput – often apply to many features/user stories. So as we create stories, we can link their acceptance criteria, as appropriate, to existing constraints. For performance requirements specific to a story, it makes sense to include them directly in its acceptance criteria.
It’s important to be mindful that user-level performance criteria can likely only be tested at the system level in a production-like environment. In the above example, I’m not going to get meaningful results for high-concurrency/high throughput tests in an environment that isn’t sized appropriately. However, the Awareness of these requirements will help you focus on other upstream performance testing-related activities that we’ll discuss.
Another common thing that’s missing for us to be able to incorporate performance testing and analysis in our pipelines is accountability. It’s not surprising that we see a lack of accountability for performance testing. There’s still much inertia around “traditional” performance testing where it was someone else’s responsibility.
I believe Awareness is an essential prerequisite to accountability – if our teams aren’t aware of what we’re trying to accomplish, we can’t hold them accountable. As we just discussed, two important ways to build Awareness are to discuss performance factors relevant to our stories early on and incorporate performance-related requirements.
We also need Visibility to achieve accountability. Awareness is one thing, but if we’re not constantly reminded how important performance is, we likely will let it slip into the background. I’ve found the best way to keep performance visible is to ensure our definition of done requires us to document performance factors and performance-related acceptance criteria as part of our work.
I’ve also seen some organizations create the role of a performance owner (one organization called it “Performance Czar”). It’s important to note that the responsibility of this role was not to “own” all performance activities — but rather ensure the teams were adopting a culture of performance accountability. They were responsible for “clearing the way” for performance by providing guidance and ensuring the teams had what they needed to implement Continuous Performance Testing.
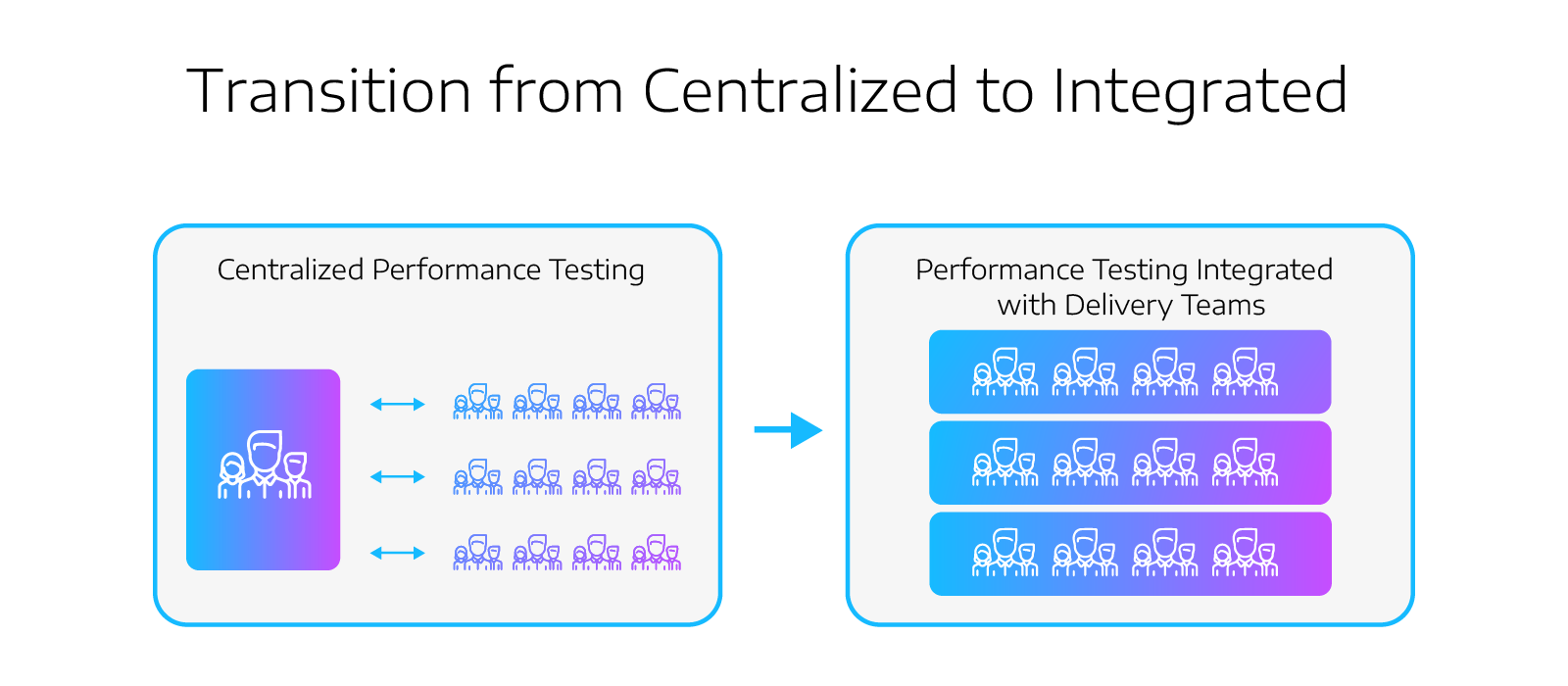
Accountability is one thing, but we can’t expect that teams will magically have the skills and tools to implement performance-related processes into the delivery cycle. You must start building the expertise within the delivery teams (I suggest one team at a time). If you are part of an organization that has (or had) a performance testing CoE, you can bring those experts into your teams to start seeding them with expertise. Once a team begins to become self-sustainable, you can start to think about expanding to other teams.
In parallel, it’s a good idea to develop a virtual CoE (or Community of Practice) that can provide guidance and oversight for performance-related activities. I’m not talking about heavy processes or management but a virtual community that can work together to share ideas and lessons learned to ensure continued improvement and growth.
It’s also important to bring the appropriate tooling into upstream environments. Not just load generation tools (which already may be in place) but also performance monitoring and diagnostics solutions that will help you understand more than just user-level metrics.
Building accountability and bringing skills and tooling into the delivery process is an excellent gateway to transitioning performance from a localized responsibility to becoming EVERYONE’S shared responsibility.
This doesn’t mean that everyone is a performance tester or engineer – but it does mean that everyone is aware of the performance and has the appropriate responsibility relative to their role.
Where can we learn about performance?
In part 2 of this post, we’ll start to look at what we can learn about performance at each stage of our delivery pipeline. I’ll use a simple pipeline to help with the conversation to discuss techniques you can use and pitfalls to avoid on your journey to Continuous Performance Testing.





Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



