
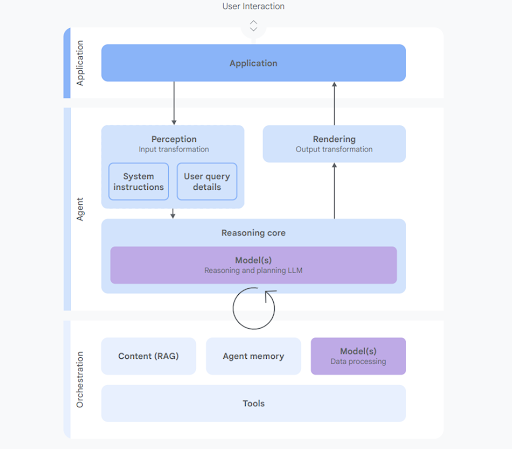
As enterprises accelerate deployment of autonomous AI agents—systems that perceive, reason, and act—the scope of risk shifts meaningfully. These agents are not simply tools; they are decision-makers integrated with real systems. Google's recent white paper, An Introduction to Google’s Approach to AI Agent Security (May 2025), provides one of the most comprehensive frameworks to date for securing such systems in enterprise environments.
Traditional security models assume determinism and bounded scope. AI agents violate both assumptions.
These behaviors demand a shift toward runtime governance, behavioral risk modeling, and layered defense enforcement.
One of the most overlooked but critical risks outlined in the paper is hallucination—where the agent generates plausible but incorrect or harmful content.
In the agent context, hallucinations go beyond factual error:
As the authors emphasize, hallucinations in agents are not benign—they can become "amplified failure modes" when coupled with action capabilities. Security controls must, therefore, treat hallucination as an adversarial vector, not just a reliability issue.
Google’s framework is built on three foundational principles designed to mitigate these risks:
To operationalize these principles, Google outlines a defense-in-depth architecture that includes:
Importantly, hallucination mitigation is not limited to prompt engineering. The authors stress the need for multi-stage output validation—especially before any external system is invoked based on the agent’s reasoning.
Organizations planning to deploy agents at scale should consider:
These mitigations do not eliminate risk entirely, but rather shift impact from the catastrophic to contained.
"Hallucinations in agents are not benign—they can become amplified failure modes."
Google’s white paper frames hallucination not as a side effect of model instability, but as a legitimate security concern—especially in systems that take autonomous action. For CTOs and CISOs, this reclassification demands new governance patterns: visibility, containment, and auditability at every stage of the agent lifecycle.
In combination with scoped privilege and human oversight, hallucination-aware architecture will define the next generation of secure, enterprise-ready AI agent systems.
Citation
Díaz, S., Kern, C., & Olive, K. (2025). An Introduction to Google’s Approach to AI Agent Security. May 2025. Google Research White Paper






Let's talk about where you are today and where you want to go - our experts are ready to help you move forward.



